
컨테이너 오케스트레이션
컨테이너의 배포, 관리, 확장, 네트워킹을 자동화하는 것. 재설계할 필요 없이 각기 다른 환경 전반에 동일한 애플리케이션을 배포하는 데에도 도움이 된다.
Kubernetes

쿠버네티스는 컨테이너화된 애플리케이션의 자동 디플로이, 스케일링 등을 제공하는 관리시스템으로, 오픈소스 플랫폼이다.
쿠버네티스는 컨테이너화된 워크로드와 서비스를 관리하기 위한 이식성이 있고, 쉽게 확장할 수 있다. 쿠버네티스는 또한 크고, 빠르게 성장하는 생태계를 가지고 있다. 쿠버네티스 서비스, 기술 지원 및 도구는 어디서나 쉽게 이용할 수 있다.
기본 개념

쿠버네티스에서 가장 중요한 것은 desired state 라는 개념이다. 쉽게 말해 사용자가 원하는 서비스, 네트워크 상태를 의미 한다. 얼마나 많은 컨테이너가 띄워져야 하는지, 몇 번 포트로 서비스해야 하는 지 등..
쿠버네티스는 이런 명세서를 토대로 띄어진 컨테이너의 현재 상태를 계속 모니터링 하면서 원하는 상태를 유지하는 일을 한다. 예를 들어 만약 컨테이너 애플리케이션을 배포하여 시중에 나온 상태일 때, 당연히 애플리케이션이 다운되지 않는 상태를 원할 것이다. 그러면 쿠버네티스가 실행 중인 컨테이너를 들여다보면서 작동이 멈추진 않았는지 꾸준히 확인해준다.
기능
- 서비스 디스커버리와 로드 밸런싱: 쿠버네티스는 DNS 이름을 사용하거나 자체 IP 주소를 사용하여 컨테이너를 노출할 수 있다. 컨테이너에 대한 트래픽이 많으면, 쿠버네티스는 네트워크 트래픽을 로드밸런싱하고 배포하여 배포가 안정적으로 이루어질 수 있다.
- 스토리지 오케스트레이션: 쿠버네티스를 사용하면 로컬 저장소, 공용 클라우드 공급자 등과 같이 원하는 저장소 시스템을 자동으로 탑재 할 수 있다.
- 롤아웃과 롤백 자동화: 쿠버네티스를 사용하여 배포된 컨테이너의 원하는 상태를 서술할 수 있으며 현재 상태를 원하는 상태로 설정한 속도에 따라 변경할 수 있다. 예를 들어 쿠버네티스를 자동화해서 배포용 새 컨테이너를 만들고, 기존 컨테이너를 제거하고, 모든 리소스를 새 컨테이너에 적용할 수 있다.
- 빈 패킹(bin packing) 자동화: 컨테이너화된 작업을 실행하는데 사용할 수 있는 쿠버네티스 클러스터 노드를 제공한다. 각 컨테이너가 필요로 하는 CPU와 메모리(RAM)를 쿠버네티스에게 지시한다. 쿠버네티스는 컨테이너를 노드에 맞추어서 리소스를 가장 잘 사용할 수 있도록 해준다.
- 복구(self-healing) 자동화: 쿠버네티스는 실패한 컨테이너를 다시 시작하고, 컨테이너를 교체하며, '사용자 정의 상태 검사'에 응답하지 않는 컨테이너를 죽이고, 서비스 준비가 끝날 때까지 그러한 과정을 클라이언트에 보여주지 않는다.
- 시크릿과 구성 관리: 쿠버네티스를 사용하면 암호, OAuth 토큰 및 SSH 키와 같은 중요한 정보를 저장하고 관리 할 수 있다. 컨테이너 이미지를 재구성하지 않고 스택 구성에 시크릿을 노출하지 않고도 시크릿 및 애플리케이션 구성을 배포 및 업데이트 할 수 있다.
장점
- 전세계적인 스케일. 구글을 비롯한 수많은 이름있는 회사들이 쿠버네티스의 생태계를 가꾸어 놓았다.
- 다양한 배포 방식. 웹 애플리케이션 말고도 다양한 형태의 애플리케이션을 배포할 수 있도록 Deployment, StatefulSets, DaemonSet, Job, CronJob등 다양한 배포 방식을 지원한다.
- 오케스트레이션의 필요성을 없애준다.
오케스트레이션의 기술적인 정의는 A를 먼저 한 다음, B를 하고, C를 하는 것과 같이 정의된 워크플로우를 수행하는 것이다. 반면에, 쿠버네티스는 독립적이고 조합 가능한 제어 프로세스들로 구성되어 있다. 이 프로세스는 지속적으로 현재 상태를 입력받은 의도한 상태로 나아가도록 한다. A에서 C로 어떻게 갔는지는 상관이 없다. 중앙화된 제어도 필요치 않다. 이로써 시스템이 보다 더 사용하기 쉬워지고, 강력해지며, 견고하고, 회복력을 갖추게 되며, 확장 가능해진다
https://subicura.com/2019/05/19/kubernetes-basic-1.html
컴포넌트
Pod

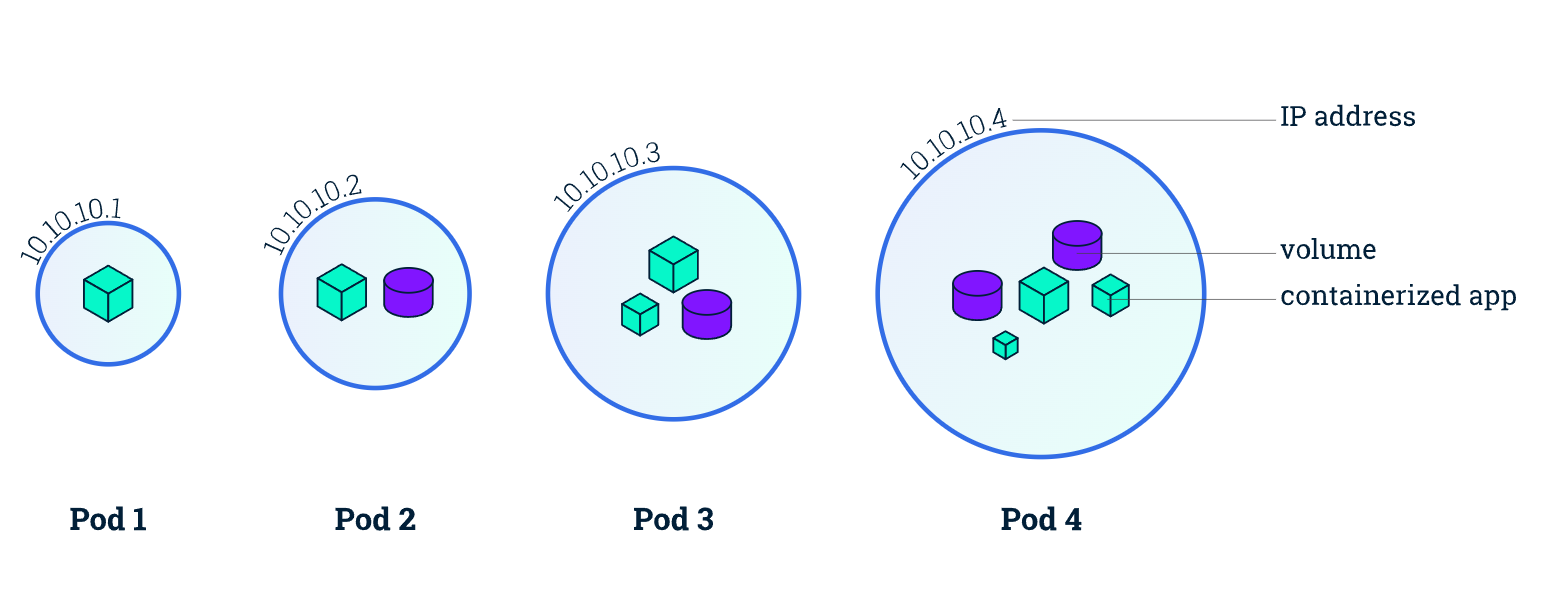
파드는 클러스터에서 작동 중인 컨테이너의 집합으로, 쿠버네티스 플랫폼 상에서 최소 단위가 된다. 각 파드 내의 컨테이너들은 다음의 자원을 서로 공유한다.
- 볼륨과 같은, 공유 스토리지
- 클러스터 IP 주소와 같은, 네트워킹
- 컨테이너 이미지 버전 또는 사용할 특정 포트와 같이, 각 컨테이너가 동작하는 방식에 대한 정보
ReplicaSet

레플리카셋은 실행되는 파드 개수에 대한 가용성을 보증하며 지정한 파드 개수만큼 항상 실행될 수 있도록 관리해준다. 즉 3개의 파드를 항상 실행 하도록 설정하면 이후 파드 1개가 삭제될 경우 다시 파드 1개가 실행되어 3개를 유지할 수 있도록 하는 것이다.
Node

노드는 컨테이너화된 애플리케이션을 실행하는 워커 머신이다. 각 노드는 컨트롤 플레인에 의해 관리된다. 파드는 노드 상에서만 동작하며 하나의 노드는 여러 개의 파드를 가질 수 있고, 쿠버네티스의 컨트롤 플레인은 클러스터 내 노드를 통해서 파드에 대한 스케쥴링을 자동으로 처리한다.
쿠버네티스에서 배포를 생성할 때, 그 배포는 컨테이너 내부에서 컨테이너와 함께 파드를 생성한다. 각 파드는 스케쥴 되어진 노드에게 묶여지게 된다. 그리고 (재구동 정책에 따라) 소멸되거나 삭제되기 전까지 그 노드에 유지된다. 노드에 실패가 발생할 경우, 클러스터 내에 가용한 다른 노드들을 대상으로 스케쥴되어진다.
Cluster
쿠버네티스를 배포하면 클러스터를 얻는다. 클러스터는 최소 한 개 이상의 노드 집합으로 이루어진다. 워커 노드는 애플리케이션의 구성 요소인 파드를 호스트 한다.

컨트롤 플레인 컴포넌트 (=master node)
- 워커 노드와 클러스터 내 파드를 관리한다. 주로 클러스터에 관한 전반적인 결정(스케줄링 등)을 수행하고 클러스터 이벤트를 감지하고 반응한다
(controller manager가 api 서버를 통해 노드 상태를 관측?).컨트롤 플레인 컴포넌트는 클러스터 내 어떤 머신(노드)에서든지 동작할 수 있다.
프로덕션 환경에서는 일반적으로 컨트롤 플레인이 여러 컴퓨터에 걸쳐 실행되고, 클러스터는 일반적으로 여러 노드를 실행하므로 내결함성(시스템의 일부 구성 요소가 작동하지 않더라도 계속 작동할 수 있는 기능)과 고가용성(사람이 개입하지 않아도 시스템이 항상 작동하며 액세스 가능하며 가동 중지를 최소화하도록 보장하는 것)이 제공됨.
- etcd: 모든 클러스터 데이터를 담는 쿠버네티스 뒷단의 key-value 저장소.
여기 안에 configMap 파일이 있고 api 서버가 이 파일을 읽고 노드가 생성되고 클러스터를 형성..? - kube-controller-manager: 컨트롤러 프로세스(api 서버를 통해 클러스터의 공유된 상태를 감시하고 현재 상태를 원하는 상태로 이행시키는 프로세스)를 실행하는 컨트롤 플레인 컴포넌트
노드 컴포넌트
- kubelet: 클러스터의 각 노드에서 실행되는 에이전트로서, 파드에서 컨테이너가 파드 스펙에 따라 확실하게 동작하도록 관리한다.
- kube-proxy: 클러스터의 각 노드에서 실행되는 네트워크 프록시. 노드의 네트워크 규칙을 유지, 관리한다.
https://kubernetes.io/docs/reference/
https://kubernetes.io/ko/docs/home/
https://www.redhat.com/ko/topics/containers/what-is-kubernetes