
Virtual memory
프로세스 전체가 메모리에 올라와 있지 않아도 실행이 가능하도록 하는 기법
당장 실행에 필요한 부분만 주기억장치(RAM)에 저장하고, 나머지는 보조기억장치(HDD)에 두고 동작하도록 하는 방법. 프로세스의 일부 메모리만 올려서 전체 프로세스를 병렬적으로 돌리게 함. 물리적 메모리에 제약을 덜 받으며 더 많은 프로세스를 한꺼번에 돌릴 수 있다.
- 장점
- 프로그래밍 용이성
- 이용률, 처리율 상성
- 단점
- 메모리 디스크 간 이동량 증가 → 속도 떨어짐, 교체 공간 확보 필요
- 페이지 부재 시 처리 방법 필요
왜 필요한가
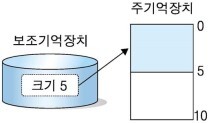
프로그램이 실행되려면 우선 주기억장치에 들어가야 하는데, 다음과 같이 크기 5의 프로그램이 실행을 위해 크기 10의 주기억장치로 들어갈 때는 아무런 문제가 발생하지 않는다.
하지만 다음의 두 경우에는 문제가 발생한다.
- 주기억장치보다 프로그램의 크기가 큰 경우
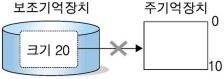
주기억장치의 크기는 10인데 프로그램의 크기가 20인 경우로, 프로그램이 주기억장치에 들어갈 수 없어 프로그램이 실행되지 못한다.
- 실행하려는 전체 프로그램의 크기가 주기억장치보다 클 때
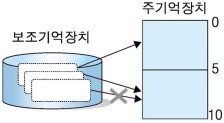
크기 5의 프로그램 3개가 동시에 실행되고자 하는 경우로 두 개의 프로그램은 주기억장치에 들어가 실행될 수 있으나 주기억장치에 들어가지 못한 나머지 한 프로그램은 실행되지 못한다.
⇒ 프로세스 전체를 한꺼번에 올리려 하기 때문에 발생하는 문제
⇒ 필요한 프로세스 일부만 올리자!
- 일부만 올려도 괜찮은 이유
→ 리스트, 배열, 테이블은 일부만 참조될 수도 있음
→ 모든 내용이 다 필요하다 해도 한꺼번에 전부를 필요하진 않기 때문
→ 잘 사용 안되는 기능도 존재
→ 예외, 오류 처리 루틴 등 잘 사용되지 않을 수도 있음
동작 과정
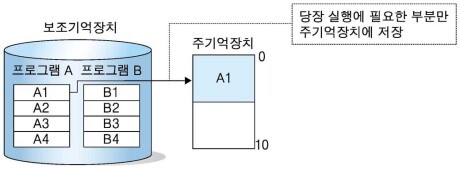
크기 10의 주기억장치에서 크기 20의 프로그램 A와 프로그램 B를 실행한다고 할 때, 당장 실행에 필요한 프로그램 A의 일부인 A1을 주기억장치에 올려 실행하고 나머지는 보조기억장치에 둔다. 물론 A2가 실행에 필요하게 되면 주기억장치로 올리면 된다.
page(swap) out
주기억장치에서 현재 사용되지 않는 영역을 보조기억장치로 옮기는 것
page(swap) in
보조기억장치에서 주기억장치로 옮기는 것
페이지, 프레임
[그림 5-45]에서 프로그램을 일정한 크기로 나누었는데, 이런 단위를 페이지(page)라 하고, 페이지 단위로 주기억장치에 올리며 동작하는 것을 페이징(paging)이라 한다. 이때 실제 주기억장치 의 페이지에 해당하는 부분을 페이지 프레임(page frame)이라 한다.
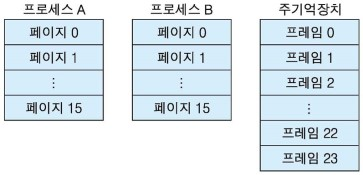
프로세스 A의 페이지 0과 프로세스 B의 페이지 0, 1이 당장 실행되어야 한다고 가정하자. 그러면 프로세스 A의 페이지 0이 주기억장치 페이지 프레임 0에, 프로세스 B의 페이지 0과 페이지 1이 주기억장치 페이지 프레임 2와 3에 저장된다고 하자. 이때 프로세스 마다 각 페이지가 주기억장치의 어느 프레임에 저장되는지를 나타내는 테이블을 MMU(메모리 관리 장치, Memory Management Unit)가 관리하는데, 이를 페이지 테이블(page table)이라 한다.
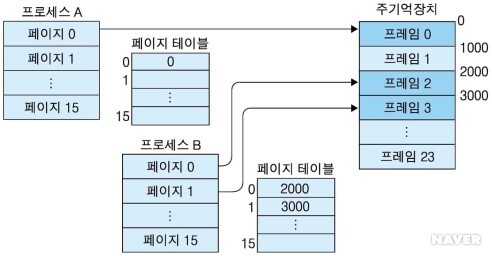
프로세스 A의 페이지 0은 페이지 프레임 0에 저장되므로 페이지 테이블 0번 항목에 페이지 프레임 0의 시작 주소인 0이 저장된다. 마찬가지로 프로세스 B의 페이지 테이블 0번 항목에 페이지 프레임 2의 시작 주소인 2000이, 1번 항목에 페이지 프레임 3의 시작 주소인 3000이 저장된다.
임의의 페이지가 실행에 필요하면 우선 주기억장치에 해당 페이지가 있는지를 확인해서 있으면 그 페이지에 접근한다. 만약 해당 페이지가 주기억장치에 없다면 보조기억장치로부터 그 페이지를 주기억장치 페이지 프레임에 저장해서 접근한다.
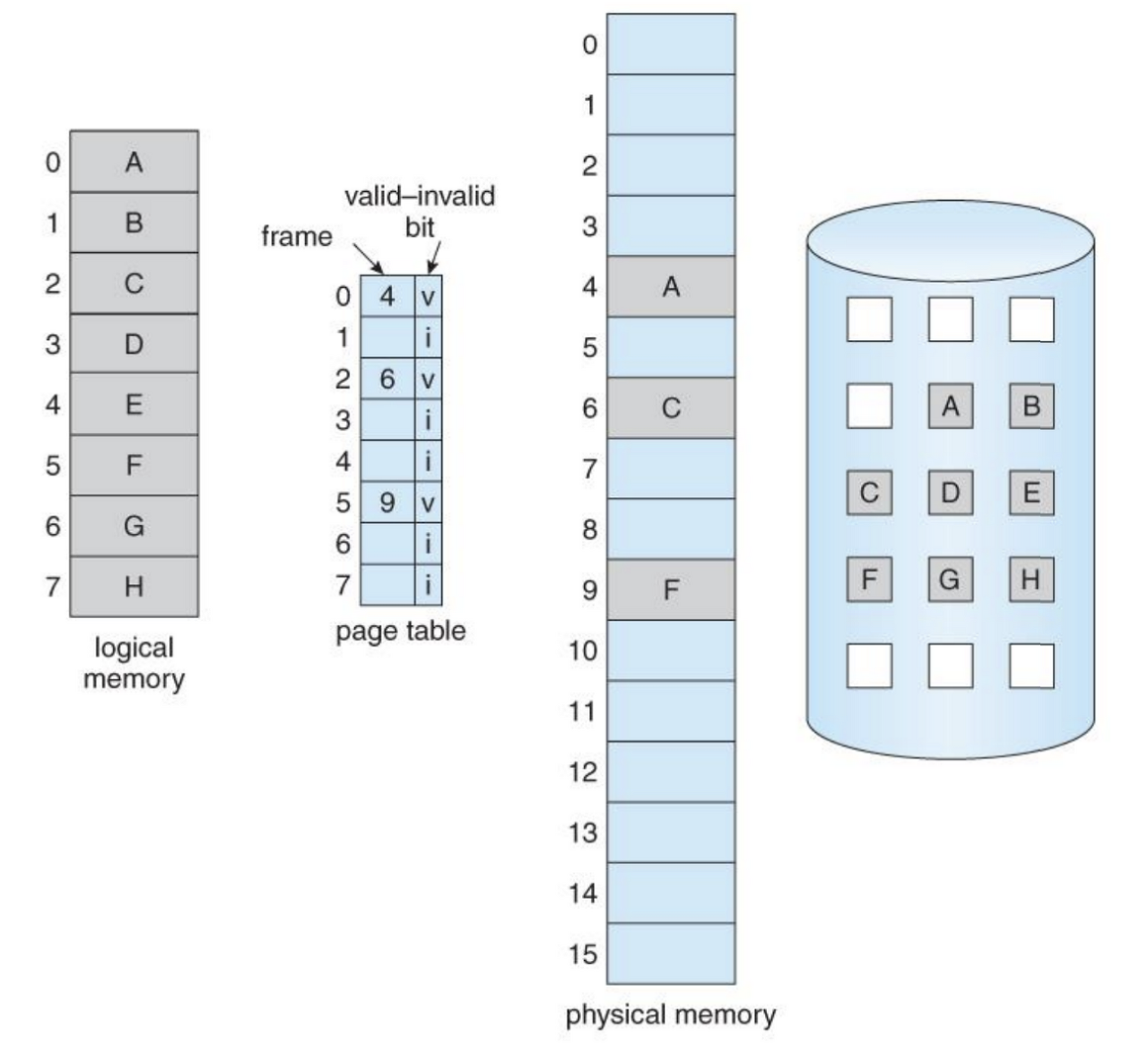
페이지 테이블에 valid-invalid bit, dirty bit(modify bit) 등의 정보를 추가로 넣을 수 있다.
- valid-invalid bit: 페이지가 현재 물리 메모리에 올라와 있는가?
- dirty bit: 페이지가 page-in된 이후 내용이 달라진게 있는가?
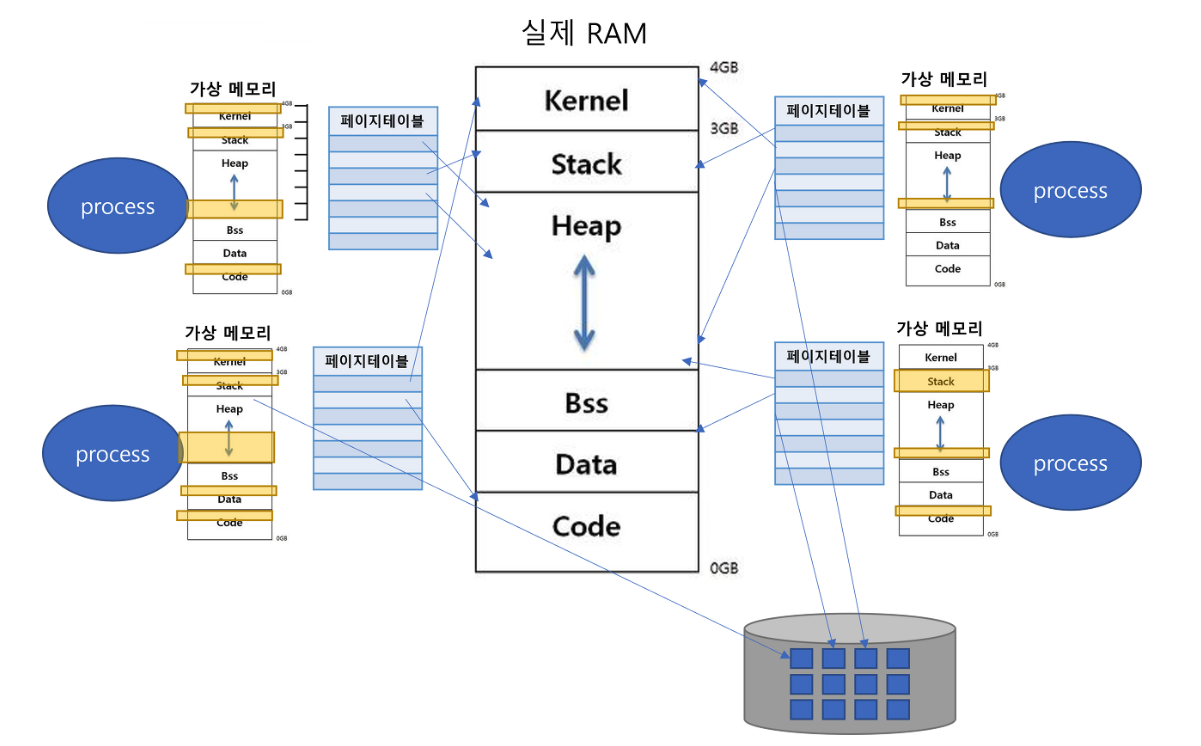
Demand Paging
당장 필요한 page를 물리 메모리에 올리는 것을 이야기한다. 이 때문에 프로세스 라이프 사이클 동안 필요 없는 영역들은 한번도 물리 메모리에 올릴 필요가 없다.
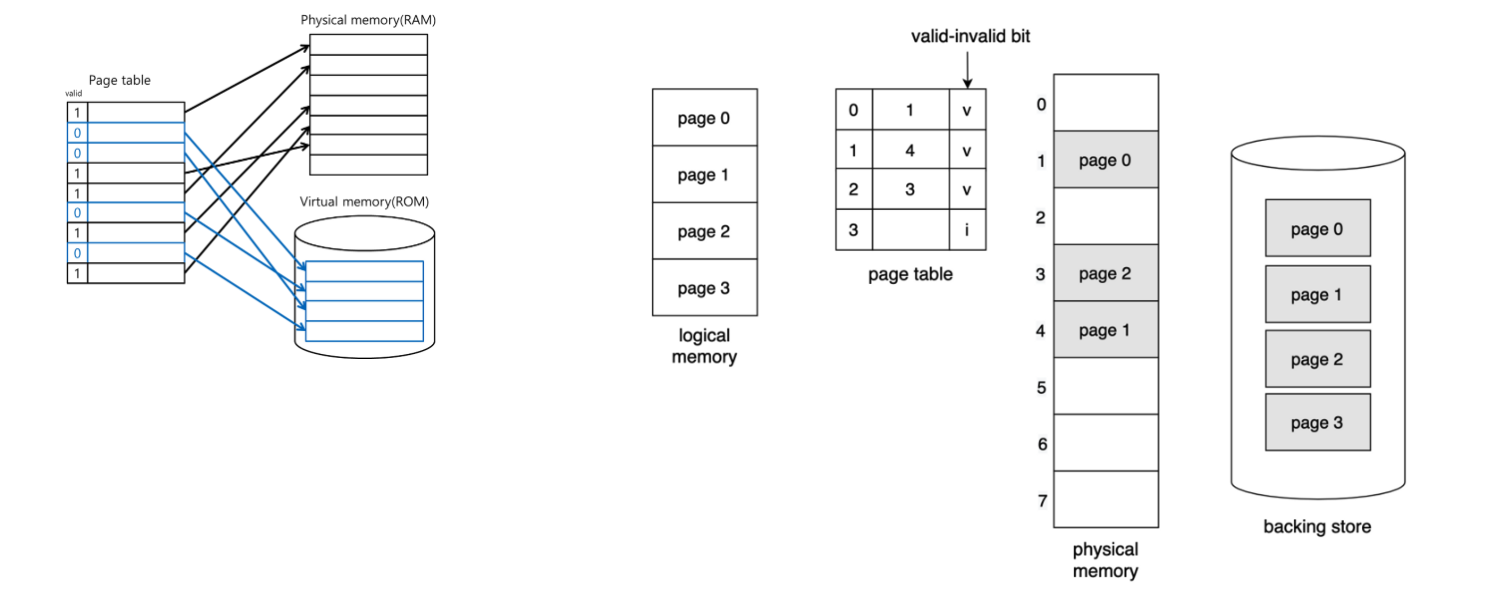
프로세스가 실행되면 당장 필요없는 영역들은 디스크와 같은 backing store에 저장되고 page 단위로 필요할 때마다 backing store에서 물리 메모리로 swap-in 된다.
copy-on-write(COW)
부모 프로세스에서 새로운 자식 프로세스가 생성될 때, 자식은 부모의 페이지 테이블 프레임 번호를 그대로 가져온다. 그러고 테이블을 부분적으로 변경해야하는 상황이 오면 그 때 부모 테이블을 복사한 사본을 수정한다.
copy를 필요할 때만 수행하기 때문에 오버헤드를 줄일 수 있다.
Page Replacement
특정 프로세스의 page를 메모리로 swap-in을 하려는데 비어있는 frame이 없을 경우 virtual memory 시스템에서는 현재 당장 사용되지 않는 frame 중 일부를 다시 backing store로 swap-out 시킨다. 이러한 과정을 page replacement라고 부른다.
동작 과정
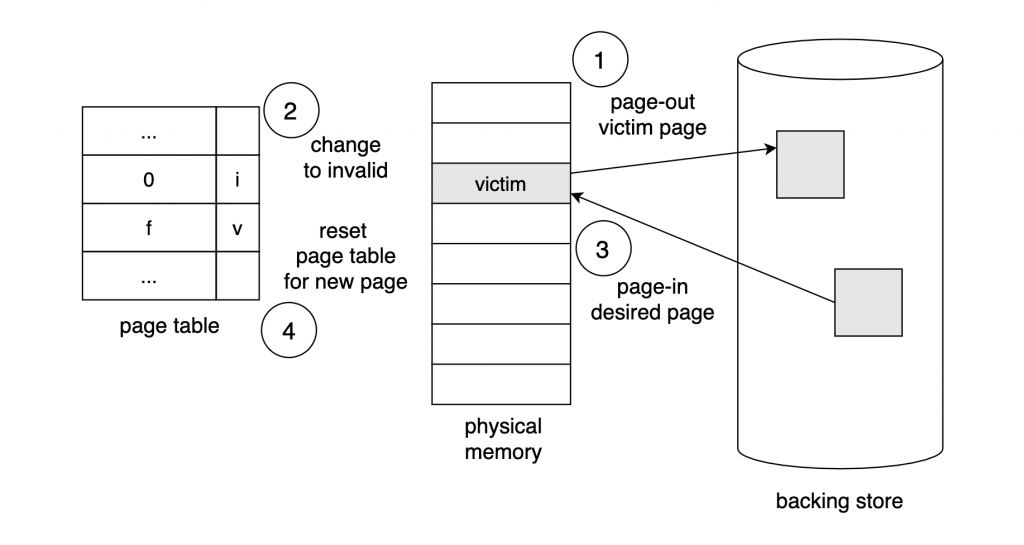
- 비어있는 frame이 없는 경우 빈 frame을 만들기 위해서 현재 올라와있는 frame들 중 swap-out 시킬 victim frame을 선정한다.
- victim frame의 내용을 backing store에 쓰고 해당 프로세스의 page table 내용을 업데이트하고 커널도 frame table과 PCB의 내용을 업데이트한다.
- 그리고 swap-in 하려는 페이지를 I/O 작업을 거쳐 빈 frame에 쓴다. 그리고 다시 page table과 frame table의 정보를 업데이트한다.
- CPU 제어권을 다시 프로세스로 넘겨준다.
위의 과정을 살펴보면 두 번의 I/O 작업이 발생한다. 이 오버헤드를 줄이기 위해서 modify bit (dirty bit) 개념이 도입되었다. CPU가 page를 읽고 쓰는 과정에서 특정 page의 내용이 변경되었다면 해당 page의 modify bit를 업데이트한다.
page-replacement 알고리즘
희생 페이지 범위 결정 방식에는 두가지가 있다.
- global replacement: 교체 알고리즘 페이지 비교 범위를 모든 프로세스의 페이지로 함
- local replacement: 해당 프로세스의 페이지만을 기준으로 함
1. FIFO(First In First Out): 가장 먼저 물리 메모리에 적재된 페이지를 선택하는 방식.
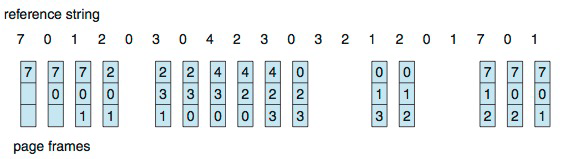
- 먼저 처음 3개는 pure demand paging이 발생한다.
- 그리고 네 번째 "2"가 들어왔을 때는 page fault가 발생하고, "7"이 제일 먼저 들어왔으니 내보낸다.
- 다음으로 다섯 번째 "0"이 들어왔다면 이미 frame에 존재하니 page hit이고, page out을 할 필요가 없다. 즉, page fault가 발생하지 않는다.
- 여섯 번째 "3"이 들어왔다면 두 번째로 들어왔던 "0"을 내보낸다. 바로 다음에 "0"을 호출하는데도 말이다.
이런 식으로 동작하다 보면 15번의 page fault가 발생한다. FIFO는 지역성을 전혀 고려하지 않고 짠 알고리즘이다.
Belady’s anomaly
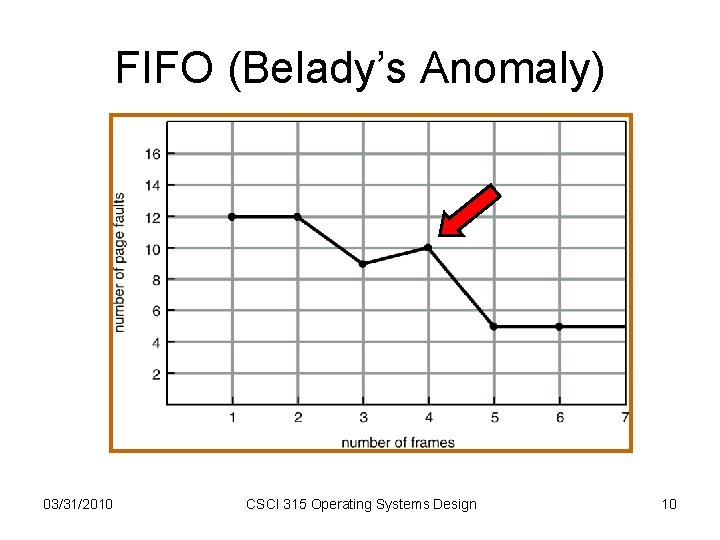
이상적으로는 페이지 크기와 page fault 수는 반비례하나 FIFO 알고리즘 사용시, 페이지 프레임을 크게 할 때 오히려 page fault가 증가하는 모순적인 상황이 발생한다.
2. LRU(Least Recent Used): 가장 오랫동안 사용되지 않았던 page를 선택하는 방식.
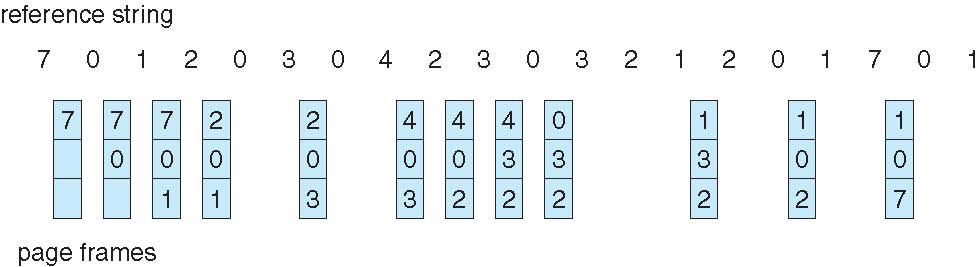
- 처음 세 개는 똑같이 들어간다.
- 네 번째 "2"가 들어왔을 때 가장 오래전에 참조했던 "7"을 뺀다.
- 여섯 번째 "3"이 들어왔을 때 가장 오래전에 참조했던 "1"을 뺀다. 원래는 "0"을 빼는 것이지만 다섯 번째에서 "0"을 참조했기 때문에 업데이트된 것이다.
이런 식으로 동작하면 12번의 page fault가 발생한다. LRU 알고리즘은 Belady's Anomaly 현상에서도 자유롭다.
3. LFU(Least Frequently Used): 가장 적게 참조되었던 page를 선택하는 방식.